Go 的字符操作
Golang 中似乎没有 StringBuffer 这种东西,今天刷题遇到需要操作字符串,如果直接使用 += 这种大力出奇迹肯定不行,所以看下别人是怎么用 Golang 进行字符添加的,发现用到了 rune 类型,遂好奇这是什么类型?
// 反转字符串
func reverseString(s string) string {
runes := []rune(s)
for from, to := 0, len(runes)-1; from < to; from, to = from+1, to-1 {
runes[from], runes[to] = runes[to], runes[from]
}
return string(runes)
}
Golang 中的字符
字符串中的每一个元素叫做 “字符”,在遍历或者单个获取字符串元素时可以获得字符。
Go 语言的字符有以下两种:
- 一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- 另一种是 rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。
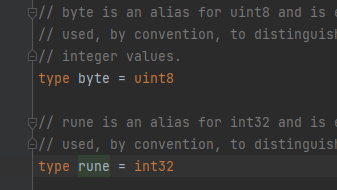
byte 类型是 uint8 的别名,对于只占用 1 个字节的传统 ASCII 编码的字符来说,完全没有问题,例如 var ch byte = 'A',字符使用单引号括起来。
rune 类型等价于 int32 类型,它用来区分字符值和整数值
计算机在底层处理的都是零和一的数字,那么字符串也不另外。string 字符串在转换成 byte 之后其实都是一个数值,我们知道常规的英文字符是 ascii 码是通过一个字节( 2^8 其实还有一位是不用的 )来存储,中国文字、日本文字常用文字就有 4000+,通过 2^8 肯定表达不了,所有可以通过 unicode 来存储,占用 2 个字节。
所以对于那些存储了汉字类型的数据应该转成 rune 类型串
runes := []rune(s)
string() 的坑
string 函数与 strconv.Itoa 函数的区别
strconv.Itoa 函数的参数是一个整型数字,它可以 将数字转换成对应的字符串类型的数字。
package main
import (
"fmt"
"strconv"
)
func main() {
string_number := 97
result := strconv.Itoa(string_number)
fmt.Println(result)
fmt.Printf("%T\n", result)
}
运行结果:
97
string
而 string() 则是把整型数字转换成 ASCII 码相同字符
package main
import (
"fmt"
)
func main() {
string_number := 97
result := string(string_number)
fmt.Println(result)
fmt.Printf("%T\n", result)
}
运行结果:
a
string
因为 ASCII 码值为 97 对应的字符是 a,所以 string(97) 的结果是 a
strconv 标准库
strconv 是 Golang 的一个标准包,实现了基本数据类型和其字符串表示的相互转换。
字符串与布尔类型
func ParseBool(str string) (value bool, err error)
返回布尔类型,可接受 1、0、t、f、T、F、true、false、True、False、TRUE、FALSE;否则返回错误。
func FormatBool(b bool) string
FormatBool 根据 b 的值返回 “true” 或 “false” 的字符串
字符串与整数类型
返回字符串表示的 64 位整数值,接受正负号。
func ParseInt(s string, base int, bitSize int) (i int64, err error)
base 指定进制(2 到 36),如果 base 为0,则会从字符串前置判断,“0x" 是 16 进制,“0" 是 8 进制,否则是 10 进制;
bitSize 指定结果必须能无溢出赋值的整数类型,0、8、16、32、64 分别代表 int、int8、int16、int32、int64;返回的 err 是 *NumErr 类型的,如果语法有误,err.Error = ErrSyntax;如果结果超出类型范围 err.Error = ErrRange。
与 ParseInt 使用相同接受无符号整数类型。
// Atoi 是 ParseInt(s, 10, 0) 的简写。
func Atoi(s string) (int, error)
FormatInt 返回 i 的 base 进制的字符串表示,base 在 2 到 36 之间。结果中使用 ‘a’ 到 ‘z’ 表示大于 10 的数值
func FormatInt(i int64, base int) string
函数同 FormatInt 功能相同针对无符号整数类型。
// Itoa 等同于 FormatInt(int64(i), 10)
func Itoa(i int) string
字符串转为浮点数
返回浮点数数值。指定 bitSize 大小设置精度:
- 32 表示 float3;
- 64 表示float64。
当 bitSize = 32 时,返回结果类型为 float64 时,也可以无损的转换为 float32。
func ParseFloat(s string, bitSize int) (float64, error)
可接受十进制和十六进制的浮点数字符串转换。如果 s 符合规则且接近一个有效的浮点数, ParseFloat 将返回使用 IEEE754 标准四舍五入的最近浮点数。如果解析十六进制浮点数时,只有在十六进制表示的数超过限定的位数时,就会进行舍入。
字符拼接 Builder
使用 strings.Builder 替换 + 进行字符串拼接,将有效地降低内存消耗。
// strings.Builder的0值可以直接使用
var builder strings.Builder
// 向builder中写入字符/字符串
builder.Write([]byte("Hello"))
builder.WriteByte(' ')
builder.WriteString("World")
// String() 方法获得拼接的字符串
builder.String() // "Hello World"
String 数组连接
var columns []string
// ...
desc := strings.Join(columns, ",")
Sprintf 格式化输出字符
这个是 fmt 包提供的一个格式字符串的包
s := fmt.Sprintf("%.4f", math.Pi) // s == "3.1416"
下面介绍下 常用的 strings 包
Search 前缀\后缀\索引
| Expression | Result | Note |
| ------------------------------------ | ------ | -------------------------------- |
| strings.Contains("Japan", "abc") | false | Is abc in Japan? |
| strings.ContainsAny("Japan", "abc") | true | Is a, b or c in Japan? |
| strings.Count("Banana", "ana") | 1 | Non-overlapping instances of ana |
| strings.HasPrefix("Japan", "Ja") | true | Does Japan start with Ja? |
| strings.HasSuffix("Japan", "pan") | true | Does Japan end with pan? |
| strings.Index("Japan", "abc") | -1 | Index of first abc |
| strings.IndexAny("Japan", "abc") | 1 | a, b or c |
| strings.LastIndex("Japan", "abc") | -1 | Index of last abc |
| strings.LastIndexAny("Japan", "abc") | 3 | a, b or c |
Replace 大小字母\小写字母\截断
// Replace first two “o” with “.” Use -1 to replace all
strings.Replace("foo", "o", ".", 2) // f..
// Apply function to each character
f := func(r rune) rune {
return r + 1
}
strings.Map(f, "ab") // bc
strings.ToUpper("Japan") // JAPAN Uppercase
strings.ToLower("Japan") // japan Lowercase
strings.Title("ja pan") // Ja Pan Initial letters to uppercase
// foo Strip leading and trailing white space
strings.TrimSpace(" foo\n")
strings.Trim("foo", "fo") // Strip leading and trailing f:s and o:s
strings.TrimLeft("foo", "f") // oo only leading
strings.TrimRight("foo", "o") // f only trailing
strings.TrimPrefix("foo", "fo") // o
strings.TrimSuffix("foo", "o") // fo
Split 切割字符串
| Expression | Result | Note |
| ------------------------------ | ---------- | ------------------ |
| strings.Fields(" a\t b\n") | ["a" "b"] | Remove white space |
| strings.Split("a,b", ",") | ["a" "b"] | Remove separator |
| strings.SplitAfter("a,b", ",") | ["a," "b"] | Keep separator |
组合和重复
| Expression | Result | Note |
| ------------------------------------- | ------ | ---------------- |
| strings.Join([]string{"a", "b"}, ":") | a:b | Add separator |
| strings.Repeat("da", 2) | dada | 2 copies of “da” |